Chainer教程 1.4 简单的CNN模型
Posted on Fri 20 July 2018 in MachineLearning • 1 min read
Chainer实现CNN模型¶
CNN全称卷积神经网络(Convolution neurual networks),其只要由两部分卷积(Conv)与池化(Pooling)组成。 卷积与池化均来源于泛函中的一种数学算子即通过两个函数f和g生成第三个函数的一种数学算子。卷积与池化最大的区别在于卷积需要训练并且卷积的步长为1,池化则不固定。
这里对步长进行一个小的说明,步长是指滤波器(卷积核)在图像上滑动时一次滑动多少单位的剂量,如下图是一个步长为2的卷积。
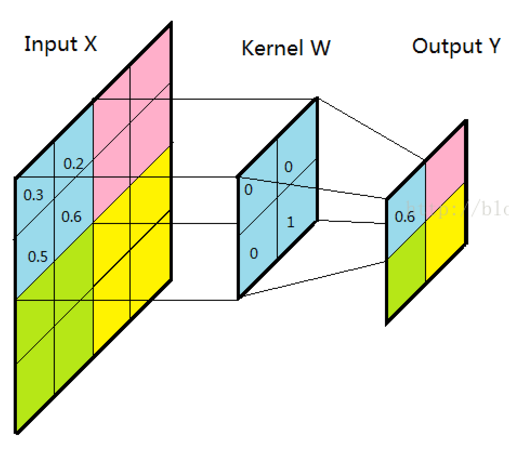
而池化一般设置为与池化核心大小相同的值,保证池化区域互不相交。
这里再说一个卷积用数学公式的表示方法$f=\omega*x + \beta$, 可以看出整体形式与全连接几乎相同,仅添加了一卷积符号。
Chainer 自构建CNN模型¶
下面利用一个小的自构建模型对Cifar10数据集进行分类
In [31]:
import chainer
import chainer.functions as F
import chainer.links as L
import chainer.datasets
import matplotlib.pyplot as plt
import chainer.optimizers
from chainer.dataset import concat_examples
from chainer.cuda import to_cpu
import numpy as np
class simple_bn(chainer.Chain):
def __init__(self,num=10):
super(simple_bn,self).__init__()
with self.init_scope():
self.conv1=L.Convolution2D(in_channels=None,out_channels=6,ksize=3,pad=1)
self.conv2=L.Convolution2D(in_channels=None,out_channels=24,ksize=3,pad=1)
self.conv3=L.Convolution2D(in_channels=None,out_channels=48,ksize=3,pad=1)
self.conv4=L.Convolution2D(in_channels=None,out_channels=96,ksize=3,pad=1)
self.conv5=L.Convolution2D(in_channels=None,out_channels=256,ksize=3,pad=1)
self.bn1=L.BatchNormalization(6)
self.bn2=L.BatchNormalization(24)
self.bn3=L.BatchNormalization(48)
self.bn4=L.BatchNormalization(96)
self.bn5=L.BatchNormalization(256)
self.fc=L.Linear(None,num)
def forward(self,x):
h=self.conv1(x)
h=F.relu(h)
h=self.bn1(h)
h=F.max_pooling_2d(h,2,2)
h=self.conv2(x)
h=F.relu(h)
h=self.bn2(h)
h=F.max_pooling_2d(h,2,2)
h=self.conv3(x)
h=F.relu(h)
h=self.bn3(h)
h=F.max_pooling_2d(h,2,2)
h=self.conv4(x)
h=F.relu(h)
h=self.bn4(h)
h=F.max_pooling_2d(h,2,2)
h=self.conv5(h)
h=F.relu(h)
h=self.bn5(h)
y=self.fc(h)
return y
# Define a network class
In [14]:
train,test=chainer.datasets.get_cifar10(ndim=3) # set shape as [n,c,x,y]
print('shape:{}'.format(train[1][0].shape))
train_iter=chainer.iterators.SerialIterator(train,128)
test_iter=chainer.iterators.SerialIterator(test,128)
plt.imshow(train[1][0].transpose(1,2,0))
#get iterator of dataset
Out[14]:

In [22]:
net=simple_bn() #instantiate a model
net.to_gpu(0) #Use gpu and 0 is gpu id
optimizer = chainer.optimizers.Adam() #use default hyperparameters
optimizer.setup(net) #bind optimizer and model
max_epoch=20
#set hyperparameter here
Chainer框架提供两种训练方式。一种为显式的调用循环,另一种即为将循环封装起来。这里主要利用显示的方法进行训练,因为更加利于在训练网络的过程中添加一些值或其他的东西。如果希望了解封装式的训练方式请进入trainer
下面是模型的训练过程,需要注意调用concat_examples方法是如果device设置不为None,这数据将会储存与Gpu中。同时该方法会自动把一个batch的数据pad成为统一大小,也就是说如果你原始的image_train中有2组数据大小分别为[3,24,32]以及[3,12,48] 那么所有的数据都会pad成为[3,24,48]的大小
In [ ]:
while train_iter.epoch<max_epoch:
train_batch = train_iter.next()
image_train, target_train = concat_examples(train_batch,device=0,padding=0)
# concat_examples can split data to x and y.
logit_train=net(image_train) #forward step
loss = F.softmax_cross_entropy(logit_train, target_train)
net.cleargrads()
loss.backward() #calculate the gradient
optimizer.update()
if train_iter.is_new_epoch:
print('epoch:{:02d} train_loss:{:.04f} '.format(
train_iter.epoch, float(to_cpu(loss.data)),), end='')
test_losses = []
test_accuracies = []
while True:
test_batch = test_iter.next()
image_test, target_test = concat_examples(test_batch,0,0)
logit_test = net(image_test)
loss_test = F.softmax_cross_entropy(logit_test, target_test)
test_losses.append(to_cpu(loss_test.data))
accuracy = F.accuracy(logit_test, target_test)
accuracy.to_cpu()
test_accuracies.append(accuracy.data)
if test_iter.is_new_epoch: #reset test_iter
test_iter.epoch = 0
test_iter.current_position = 0
test_iter.is_new_epoch = False
test_iter._pushed_position = None
break
print('val_loss:{:.04f} val_accuracy:{:.04f}'.format(
np.mean(test_losses), np.mean(test_accuracies)))
如果需要对模型保存以及加载,则需要使用以下代码
from chainer import serializers
serializers.save_npz('where to save',net)
serializers.load_npz('where to load',net)